
# DBSCAN 密度聚类算法
# 1. DBSCAN原理
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise, 具有噪声的基于密度的聚类方法)
- 密度聚类原理: 通过将紧密相连的样本划分为一类, 这样就得到了一个聚类类别. 通过将所有各组紧密想来你的样本划为各个不同的类别, 就得到的最终的聚类结果
- 优点
- 不需要设置分类个数
- 适用于任意形状数据
- 对异常点数据不敏感
- 聚类结果没有偏倚
- 缺点
- 样本密度不均匀, 聚类间距相差很大时, 聚类效果较差
- 样本集较大时, 聚类收敛时间较长
- 调参相对复杂
# 2. 源码
基于sklearn的DBSCAN
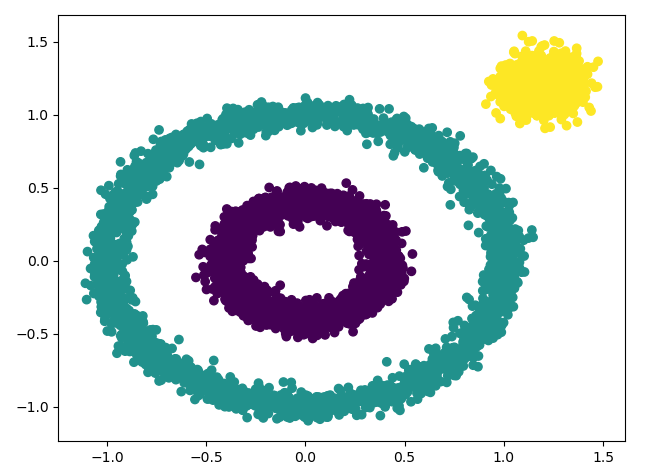
from sklearn.datasets import make_circles, make_blobs import matplotlib.pyplot as plt from sklearn.cluster import DBSCAN import numpy as np # 创建数据集 # 环形分布数据: 样本点数, 内圈外圈距离之比, 噪声点的标准差 x1, y1 = make_circles(n_samples=5000, factor=.6, noise=.05) # 团状分布数据: 样本点数, 数据维度, 中心点, 标准差 x2, y2 = make_blobs(n_samples=1000, n_features=2, centers=[[1.2, 1.2]], cluster_std=[.1]) # 数组拼接 x = np.concatenate((x1, x2)) # eps: 邻域的距离阈值, 默认0.5 # min_samples: 领域的样本数阈值, 默认值5 # metric: 最近邻距离度量参数, 默认欧氏距离 y_pred = DBSCAN(eps=0.1).fit_predict(x) plt.scatter(x[:, 0], x[:, 1], c=y_pred) plt.show()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22效果
← 机器学习目录 K-Means 聚类算法 →